Batch Convert Office Documents to PDF
 If you have Microsoft Office or OpenOffice installed, you can use SimpleIndex to automatically convert MS Office documents to PDF files for archival. PDF files are better for archival than editable formats like Word and Excel. They can be annotated, encrypted, searched and viewed with free PDF readers.
If you have Microsoft Office or OpenOffice installed, you can use SimpleIndex to automatically convert MS Office documents to PDF files for archival. PDF files are better for archival than editable formats like Word and Excel. They can be annotated, encrypted, searched and viewed with free PDF readers.
There are many free applications that let you convert documents to PDF one at a time. SimpleIndex lets you convert thousands of files at once while it also extracts data from the text for indexing or data entry automation. This feature is ideal for migrating or archiving Office documents to SharePoint, document management systems and custom web applications.
SimpleIndex can read data from filled-in PDF forms and use it to index documents, export to CSV, XML or any database. SimpleIndex can also fill in blank PDF forms using data extracted from documents or contained within a database or Excel file.
Take control of Sales Tax exemption forms
Automatically fill and file sales tax forms
Ben Franklin once noted, “…nothing is certain except death and taxes.” In the case of state sales taxes, they may be unavoidable, but managing your customers’ sales tax exemption forms and making sure you’ve sent current exemption certificates to your vendors doesn’t have to feel like a terminal condition.

SimpleIndex has the power to recognize the forms you receive from customers and file them automatically so you can find them in seconds.
SimpleIndex also fills out sales tax exemption PDFs from every state to create a complete set of your forms ready for emailing to your vendors.
Link both processes to your customer and vendor data sources to streamline the process. Even without those lists, the state, certificate number and expiration recognize automatically, leaving you with the simple task of clicking on the customer name to file the document away.

You’ll never have to dig through old emails or piles of paper to make sure you have that exemption on file again!
When it’s time to send your vendors the proper state certificate to get your sales tax exemption, simply open up the Fill Vendor Form job, select the vendor, and all your state exemptions are filled out automatically and assembled into one PDF file suitable for framing emailing.
Manage your customer sales tax exemption forms:
- Scan customer sales tax exemption certificates submitted on paper
- Process e-mailed PDF sales tax exemption forms
- Use OCR or read the filled-in forms from PDF files to file them automatically
- Search and view customer tax forms in seconds
- Receive automatic e-mail notifications when exemptions expire
Fill out and e-mail vendor sales tax exemption forms:
- Standardized, fillable PDF sales tax forms for every state
- Select a vendor and fill in all the relevant name and address information automatically
- One click fills in every state form with both your company’s information and your vendor’s
- Packages saved to bookmarked PDF files and e-mailed to vendors
- Receive automatic e-mail notifications when exemptions expire
Find out more!
The sales tax management solution is available for free to SimpleIndex users!
Download SimpleIndex – Download the Sales Tax Jobs
Some initial setup is required, and we can help you out with that too. Our Professional Services department can have you up and running in just a couple of hours.
Please Contact Us to find out more about automating your sales tax time thieves with SimpleIndex!
Learn More:









Large Documents (>500 pages) are Slow to Process
When working with PDF image files containing a high number of pages (typically in excess of 500, but can vary by file and PC running the job) SimpleIndex may run into performance issues as it attempts to hold all of those pages in memory and perform the requested operations (full-text OCR in particular can tax a system in these circumstances).
SimpleIndex 11:
Use the Fast Import and Fast Export options to use our new, optimized import and export that can split or merge PDF files with thousands of pages in a matter of seconds. These options disable the optional features that require the slower import and export operations and allow for much faster processing.
Older Versions of SimpleIndex:
A workaround in this scenario is to convert the large PDF to a folder of smaller PDFs files that can be managed more easily. In order to minimize the impact on production and tax the user(s) with extra steps, you can use a third-party splitting tool that can be called from the Command Line. One such option that has worked well is PDFSplitter from CoolUtils
One way to automate this process is to use PDFSplitter’s command line ability in conjunction with SimpleIndex’s Pre-processing function. For simplicity let’s consider a 600 page PDF with a filename generated at the time of scanning using indexes provided on a coversheet or keyed by an operator. The goal now is to take that large file and perform a full-text conversion on it.
Our SimpleIndex job, Full Page OCR.sic let’s say, launches and before getting to work calls PDFSplitter from the Pre-processing step with a command such as
PDFSplitter.exe “C:\Images\Smith – John – Medical History.pdf” C:\Images\Pages\ -cp 100
PDFSplitter will run and break that document every 100 pages creating 6 PDFs in the folder C:\Images\Pages. It maintains the original filename, simply adding “001-100” and so on to the name. After PDFSplitter is complete the Full Page OCR job begins its process and, given that the original filename is still part of the split files’ naming schema, it can produce one full-text PDF in the final output folder.
Related Wiki Help Pages:
How to activate SimpleView?
Please refer to the Wiki Documentation for the complete SimpleView Application reference.
Activation Instructions
SimpleView Option A – New SimpleIndex Installation:
If you are installing SimpleView on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Demo Installation Link.Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.

During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:

Multiple Serial Codes (separate with a comma):

After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:

SimpleView Option B – SimpleView Already Installed:
If you have already installed the SimpleView software then all you need to do is Activate the demo.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.

Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.

You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleView Option C – SimpleView Installed on Computer Not Connected to the Internet:
If you would like to install SimpleView on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleView software without activation.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
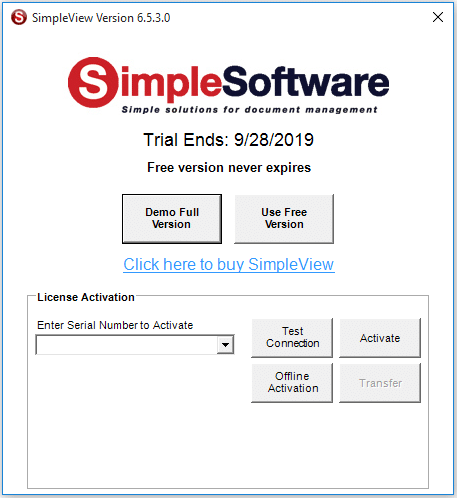
Click the “Offline Activation” button.

Click OK in the “SimpleView Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleView Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
How to activate any Add-on or Upgrade to SimpleIndex?
Please refer to the Wiki Documentation for the complete Licensing & Activation reference.
SimpleIndex Add-on Option A – New SimpleIndex Installation:
If you are installing SimpleIndex on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Download Page.
Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.
During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:
Multiple Serial Codes (separate with a comma):
After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:
When you click Finish you will receive the Global Settings Wizard window to configure the general settings for SimpleIndex on the installed computer.

Move through the prompts to configure the Global Settings Wizard. Once complete you will receive a confirmation that the License was properly activated before the software opens.
SimpleIndex Add-on Option B – SimpleIndex Already Installed:
If you have already installed the SimpleIndex software then all you need to do is Activate the demo.
Click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and Select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.
You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleIndex Add-on Option C – SimpleIndex Installed on Computer Not Connected to the Internet:
If you have installed SimpleIndex on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleIndex software without activation.
Once it has been fully installed click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
Click the “Offline Activation” button.
Click OK in the “SimpleIndex Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleIndex Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
TaxStacker: Sort & Classify Federal Tax Documents
This is a great way for accountants and tax preparers to organize complex tax returns in a way that makes it easy to find specific documents. It can also be used to ensure all required schedules and supporting documents are present in the finished return.
Use our out-of-the-box TaxStacker configuration to automatically identify all the forms and schedules that make up a U.S. federal income tax return. These can then be sorted into separate PDF files or combined into a single file that has bookmarks to indicate each section.
Learn More:
Check and Repair All PDF Files
Please refer to the Wiki Documentation for the complete PDF reference.
You can set SimpleIndex to assume that it needs to check every PDF file and fix it.
Go to this location in the Windows Registry:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
Create a New String Value called “FixAllPDF” and set the value to 1

Is SimpleIndex for Windows only? I’m a Mac user.
Please refer to the Wiki Documentation for the complete Installation reference.
Unfortunately SimpleIndex is for Windows only. This is true of most high speed document scanning applications, due to the fact that most document scanners only have Windows drivers.
However, SimpleIndex can output to databases and file shares on a Mac server. The fact that it does not have its own proprietary file system and database makes it a very good choice for Mac networks, since only the scanning workstation needs to be a PC.
Likewise, many users have reported great success running Parallels or Bootcamp on their Mac to allow the use of a Windows OS
- Published in Licensing & Installation
How much do Simple Software products cost?
Click here for the latest pricing and online ordering information. You can also purchase full service solutions from one of our Authorized Dealers.
Click here for a PDF version of the price list and a feature matrix that shows which features are included in each version.
All applications are activated online by entering a serial number in the demo. The serial is emailed to you once your order is processed.
- Published in Licensing & Installation, LoanStacker, SimpleCoversheet, SimpleExport, SimpleQB, SimpleSend, SimpleView
On what versions of Windows does SimpleIndex run?
SimpleIndex will run on Windows 11, 10, 8, 7, Vista, 2008 editions.
It would not run on Windows ME or NT.
SimpleIndex 8.3 and below are compatible with Windows XP, Server 2003 and Windows 2000.
- Published in Licensing & Installation
MS Office & PDF Text Parsing

Office Videos | PDF Video
The template and dictionary matching capabilities of SimpleIndex‘s OCR function can be used to extract index information from the text of existing MS Office and PDF files, or any file with an accompanying TXT file. SimpleIndex® will search the document for matches on unique patterns and value lists, then index the document with the matching data. Zone coordinates can be set to limit the search area to pre-defined regions on standard forms. The result is a fully automated indexing and renaming process for all your electronic documents!
Using existing text, SimpleIndex can index and rename hundreds of files each minute and achieve perfect accuracy. These files can then be quickly searched with SimpleIndex Retrieval, SharePoint and Google search engines, or uploaded into your company’s document/content management system or custom business applications.
Enhanced Text Parsing & PDF Support
MS Office and PDF text parsing features are now included in the Basic version of SimpleIndex, making it much more affordable to enable automatic document sorting on the desktop. Additional Office and PDF features include:
- Convert any MS Office, HTML, XML and image files to PDF before processing
- Read and write password protected PDF file
- Searchable PDF output (Image + Hidden Text)
- Interactive template builder and tester
- Easily select PDF or PDF/A output format
- Native PDF viewer and auto-repair of problematic PDFs
- Read data from PDF forms
- Populate blank PDF forms with index data
Batch Convert Office Documents to PDF
If you have Microsoft Office or OpenOffice installed, you can use SimpleIndex to automatically convert MS Office documents to PDF files for archival. PDF files are better for archival than editable formats like Word and Excel. They can be annotated, encrypted, searched and viewed with free PDF readers.
There are many free applications that let you convert documents to PDF one at a time. SimpleIndex lets you convert thousands of files at once while it also extracts data from the text for indexing or data entry automation. This feature is ideal for migrating or archiving Office documents to SharePoint, document management systems and custom web applications.
Quickly Organize Any File on Your Computer
SimpleIndex lets you process any type of file on your computer. If an OLE-enabled viewer is installed, SimpleIndex will display the document on the screen. Other documents can be opened automatically in their default application when they are indexed. Quickly type index field data that can be used to reorganize the files into subfolders and structured filenames for browsing and searching on your network, or uploaded to your document/content management system or custom business application.
If the file has an accompanying text file (*.TXT) with the same name, the text in that file can be used for index field extraction, fully automating the process.
Viewing & Indexing MS Office Documents
SimpleIndex features full support for viewing and editing MS Office documents (Word, PowerPoint and Excel) on computers with or without MS Office installed. The full application interface is displayed within the SimpleIndex viewer, letting users view the full content of the documents, edit them with all the features of MS Office and save the changes. Modify privileges can be denied using Windows file security or by the SimpleIndex administration wizard to keep out unauthorized changes.
If MS Office is not installed, SimpleIndex can open and display them in the built-in viewer in read-only mode.
Learn More:
KB Articles for MS Office & PDF Text Parsing
- Change the Dictionary Separator Value
- Regular Expression (RegEx) - Syntax or Type
- Check and Repair All PDF Files
- Keep Pages in Original Order when Bookmarking
- Do Not Combine Pages to 1 Bookmark
- Can I split a PDF based on bookmark values?
- Is it possible to search for and retrieve documents with Windows desktop search?
- Can SimpleIndex read bar codes from existing PDF files?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- How do you configure OCR to read index information from MS Office or PDF documents?
