An essential first step to processing mixed batches with many types of documents is classification. Document Classification methods quickly sort documents by type using key content and layout attributes to identify them.
The most popular document classification systems are advanced AI-based machine learning algorithms that automatically learn how to classify documents based on samples and user feedback. These systems are very powerful but also very expensive. Only large organizations processing millions of pages each year can afford these enterprise solutions.
SimpleIndex naturally has a simpler way to do classification based on keyword patterns in the document text. Simply create a list of document types and assign one or more unique keywords or phrases that will only appear in that document type to each. Logical operators for AND, OR and NOT prevent false matches by requiring multiple keywords for matching or excluding documents that contain certain phrases.
Keyword-based classification works for the vast majority of applications at a fraction of the cost of AI classification.
After classification, SimpleIndex can automatically launch separate document indexing workflows for each document type found in the classified batch. This is especially useful when documents have different metadata requirements or business workflows associated with them.
Zone OCR and Dynamic OCR

Other document scanning applications in this price range use Zone OCR to obtain index data from the page.
SimpleIndex improves upon this time-tested but limited model with its Dynamic OCR feature.
Let’s look at the difference between the two methods:
Zone OCR
Zone OCR is used to read document indexes or tags from text on the page. It is a great way to automate the data entry associated with scanning documents.
However, there are several limitations to zone OCR that must be overcome:
- Index information must be in the exact same place on every page
- Documents shift and skew during scanning, causing the zones to not line up
- If surrounding lines or text on the document are too close, they can encroach on the zone
Dynamic OCR
SimpleIndex overcomes these limitations by using Dynamic OCR technology to extract values from anywhere on the page. Our simplified version of Dynamic OCR works great for many types of documents at a fraction of the cost of other solutions.
- Index information can appear anywhere
- Unwanted characters are ignored
- Find unique patterns of letters and numbers using Template Matching
- Use Dictionary Matching to find a value from a list of possible values
- Use Cloud OCR or ChatGPT to perform AI analysis and intelligent data extraction

Dynamic OCR and AI Assisted OCR
AI assisted OCR is the popular solution to the problem of unstructured and semi-structured documents. But there are many scenarios where simple Template and Dictionary matching provide much better results. And all of these solutions are much more expensive than SimpleIndex!

Often there are only a few key values that need to be extracted, and a wide variety of possible layouts. AI-based document training requires manual processing of several samples of each possible format before it learns how to read them reliably, where a Template could read them all with a single setting. Dictionary matching can perform advanced classification without analyzing thousands of samples.
When data extraction requires natural language processing, field label extraction, handwriting, AI document analysis, or other advanced features, SimpleIndex offers Cloud OCR and ChatGPT integrations.
Dynamic OCR Examples
In the video we see how SimpleIndex approaches a typical Zone OCR example. With SimpleIndex you can use large zones that give a wide margin for error. Template and Dictionary matching are then used to extract the 7-digit Account Number, 6-digit Order Number and Company Name. SimpleIndex discards the surrounding text and keeps the correct value.
Another common example is finding a unique identifier, for example a social security number, that could appear anywhere on the page. Simply enter the template ###-##-#### and SimpleIndex will search the full OCR text until it finds a match. Since only one social security number is likely to appear on the page, a match on this pattern is almost certainly the required value.
With dictionary matching, you can give SimpleIndex a list of possible values and it will automatically search the zone or page for each possible value until it finds a match.
Many dynamic forms processing applications can be implemented using these simple algorithms. This makes SimpleIndex far more versatile than other zone OCR solutions that require the index value to be in the exact same location on every page. Yet SimpleIndex costs only a fraction of the price!
SimpleIndex‘s dynamic forms processing can greatly speed up data entry by eliminating a good percentage of indexing work. For many this can put the labor cost of scanning within their reach.
Dynamic OCR can also be applied to MS Office and PDF files, creating a fully automated process for intelligently indexing and reorganizing electronic documents.

Amazon AWS Textract Cloud OCR
With Textract you can capture data from almost any type of form, including handwritten ones! Textract identifies labeled text anywhere on the document and returns the label text along with the corresponding value. Map the labels to index fields in SimpleIndex and you are ready to capture that data no matter where it appears on the page.

Textract uses machine learning with a huge model based on the billions of pages processed using Textract to provide the most accurate OCR and form field extraction solution available.
By default, Textract is only available as an API and requires custom coding to integrate it into your document workflows. SimpleIndex turns it into a fully-featured batch document and data processing app that is ready to use out-of-the-box.
Since there are no templates to configure or train, setup can be done in hours instead of days or weeks months required by other enterprise data capture solutions.
Pay-as-you-go pricing makes SimpleIndex with Textract the most affordable way to batch process forms for projects with less than 50,000 pages per year to process, especially if you need to read handwriting or have forms with many layout variations.
Got a preference for ABBYY Cloud OCR, Microsoft Azure AI Vision, or Google Cloud Vision OCR? These can be quickly added for a small customization fee. Contact Us for a quote!
Wiki: How to configure AWS Textract OCR in SimpleIndex
Handprint and Handwriting Recognition

SimpleIndex 11 adds handprint recognition capabilities to the FineReader OCR engine to allow recognition of simple form fields and printed text. It works best with constrained form fields, with letter boxes for each character like you see on tax forms and credit applications. And no additional licensing or per-page costs are required!
For unconstrained handprint and cursive handwriting, use the Cloud OCR option to achieve the best recognition accuracy available. This option requires additional AWS processing fees for each page.
Support for Regular Expressions
SimpleIndex OCR has a simple built-in template format, as well as support for Regular Expressions. Regular Expressions (RegEx for short) let you define complex search patterns to extract matching values from the text. This greatly enhances the functionality of the dynamic OCR in SimpleIndex, making it capable of finding variable-length fields with no distinct pattern.
Regular Expressions are a commonly used in text parsing applications. The Perl programming language makes extensive use of RegEx, as do UNIX utilities like “grep”. Many programmers and IT personnel are already familiar with RegEx and can create complex expressions without specific training.
Click here for a reference guide to Regular Expressions
How to Configure SimpleIndex OCR
Our Wiki help has extensive information on how to configure OCR for various document and data capture scenarios.
- Zone OCR read data in a specific location
- Template matching to match unique patterns
- Dictionary matching to match a list of possible values
- OCR Options OCR job settings that apply to all fields
- File Formats that can be output by OCR
- Languages supported by OCR
- FineReader versus Tesseract OCR engines
- Searchable PDF with MRC compression
- OCR to Field for point and click OCR during verification
- Cloud OCR using Textract
Watch this Simple Software University training video to see how to configure and run an OCR job with SimpleIndex.
Learn More:









KB Articles for Optical Character Recognition (OCR)
- Language Pack for Standard/Tesseract OCR
- Languages Supported in SimpleSoftware OCR Engines
- What is Document Imaging?
- Change the Dictionary Separator Value
- Change the OCR Font or Type
- Regular Expression (RegEx) - Syntax or Type
- Autonumber Increment Value
- I'm using full page OCR. The information is all appearing in the txt file but it is losing format about half way through. Data to the right is ending up at the end of the txt doc. Can this be fixed?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- If I have a form which is filled manually by hand, can SimpleIndex read the data from it?
Large Documents (>500 pages) are Slow to Process
When working with PDF image files containing a high number of pages (typically in excess of 500, but can vary by file and PC running the job) SimpleIndex may run into performance issues as it attempts to hold all of those pages in memory and perform the requested operations (full-text OCR in particular can tax a system in these circumstances).
SimpleIndex 11:
Use the Fast Import and Fast Export options to use our new, optimized import and export that can split or merge PDF files with thousands of pages in a matter of seconds. These options disable the optional features that require the slower import and export operations and allow for much faster processing.
Older Versions of SimpleIndex:
A workaround in this scenario is to convert the large PDF to a folder of smaller PDFs files that can be managed more easily. In order to minimize the impact on production and tax the user(s) with extra steps, you can use a third-party splitting tool that can be called from the Command Line. One such option that has worked well is PDFSplitter from CoolUtils
One way to automate this process is to use PDFSplitter’s command line ability in conjunction with SimpleIndex’s Pre-processing function. For simplicity let’s consider a 600 page PDF with a filename generated at the time of scanning using indexes provided on a coversheet or keyed by an operator. The goal now is to take that large file and perform a full-text conversion on it.
Our SimpleIndex job, Full Page OCR.sic let’s say, launches and before getting to work calls PDFSplitter from the Pre-processing step with a command such as
PDFSplitter.exe “C:\Images\Smith – John – Medical History.pdf” C:\Images\Pages\ -cp 100
PDFSplitter will run and break that document every 100 pages creating 6 PDFs in the folder C:\Images\Pages. It maintains the original filename, simply adding “001-100” and so on to the name. After PDFSplitter is complete the Full Page OCR job begins its process and, given that the original filename is still part of the split files’ naming schema, it can produce one full-text PDF in the final output folder.
Related Wiki Help Pages:
How to activate SimpleView?
Please refer to the Wiki Documentation for the complete SimpleView Application reference.
Activation Instructions
SimpleView Option A – New SimpleIndex Installation:
If you are installing SimpleView on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Demo Installation Link.Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.

During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:

Multiple Serial Codes (separate with a comma):

After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:

SimpleView Option B – SimpleView Already Installed:
If you have already installed the SimpleView software then all you need to do is Activate the demo.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.

Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.

You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleView Option C – SimpleView Installed on Computer Not Connected to the Internet:
If you would like to install SimpleView on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleView software without activation.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
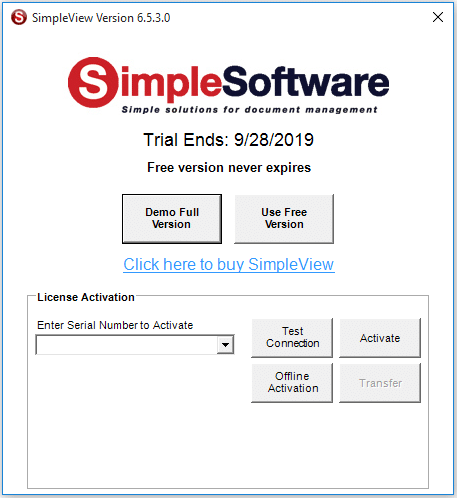
Click the “Offline Activation” button.

Click OK in the “SimpleView Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleView Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
How to activate any Add-on or Upgrade to SimpleIndex?
Please refer to the Wiki Documentation for the complete Licensing & Activation reference.
SimpleIndex Add-on Option A – New SimpleIndex Installation:
If you are installing SimpleIndex on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Download Page.
Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.
During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:
Multiple Serial Codes (separate with a comma):
After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:
When you click Finish you will receive the Global Settings Wizard window to configure the general settings for SimpleIndex on the installed computer.

Move through the prompts to configure the Global Settings Wizard. Once complete you will receive a confirmation that the License was properly activated before the software opens.
SimpleIndex Add-on Option B – SimpleIndex Already Installed:
If you have already installed the SimpleIndex software then all you need to do is Activate the demo.
Click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and Select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.
You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleIndex Add-on Option C – SimpleIndex Installed on Computer Not Connected to the Internet:
If you have installed SimpleIndex on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleIndex software without activation.
Once it has been fully installed click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
Click the “Offline Activation” button.
Click OK in the “SimpleIndex Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleIndex Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
Check and Repair All PDF Files
Please refer to the Wiki Documentation for the complete PDF reference.
You can set SimpleIndex to assume that it needs to check every PDF file and fix it.
Go to this location in the Windows Registry:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
Create a New String Value called “FixAllPDF” and set the value to 1

Is SimpleIndex for Windows only? I’m a Mac user.
Please refer to the Wiki Documentation for the complete Installation reference.
Unfortunately SimpleIndex is for Windows only. This is true of most high speed document scanning applications, due to the fact that most document scanners only have Windows drivers.
However, SimpleIndex can output to databases and file shares on a Mac server. The fact that it does not have its own proprietary file system and database makes it a very good choice for Mac networks, since only the scanning workstation needs to be a PC.
Likewise, many users have reported great success running Parallels or Bootcamp on their Mac to allow the use of a Windows OS
- Published in Licensing & Installation
Is it possible to search for and retrieve documents with Windows desktop search?
Please refer to the Wiki Documentation for the complete Searchable PDF reference.
Windows Search works great with SimpleIndex because all index data can be saved to the folder and file names as well as the file properties, and OCR text can be saved to hidden layers in PDF files. Windows Search will read all of these elements when building its index and will return any matching files when you search.
Using Windows Search on a file server allows for instantaneous searching across terabytes of documents and text for all of the users on your network.
IFilters allow Windows Search to search within file contents.
Here are three popular PDF IFilters that will enable text searching for PDF files:
- Foxit PDF IFilter (commercial)
- TET PDF IFilter (free/commercial)
- Adobe PDF IFilter (32-bit / 64-bit) (free)
If you have issues with PDF text searching in Windows 10, this article has detailed instructions for resolving PDF IFilter issues:
https://fixedit.itxpress.biz/2018/07/05/searching-pdfs-in-windows-10/
- Published in Database & Retrieval, Export, Office PDF Text Processing
How much do Simple Software products cost?
Click here for the latest pricing and online ordering information. You can also purchase full service solutions from one of our Authorized Dealers.
Click here for a PDF version of the price list and a feature matrix that shows which features are included in each version.
All applications are activated online by entering a serial number in the demo. The serial is emailed to you once your order is processed.
- Published in Licensing & Installation, LoanStacker, SimpleCoversheet, SimpleExport, SimpleQB, SimpleSend, SimpleView
On what versions of Windows does SimpleIndex run?
SimpleIndex will run on Windows 11, 10, 8, 7, Vista, 2008 editions.
It would not run on Windows ME or NT.
SimpleIndex 8.3 and below are compatible with Windows XP, Server 2003 and Windows 2000.
- Published in Licensing & Installation
I’m using full page OCR. The information is all appearing in the txt file but it is losing format about half way through. Data to the right is ending up at the end of the txt doc. Can this be fixed?
Please refer to the Wiki Documentation for the complete Full-Page OCR reference.
SimpleIndex version 7 solves this problem with the incorporation of the FineReader OCR engine. Full text in PDFs will now flow with the formatting of the PDF.
Legacy Versions: SimpleIndex can also be used with other OCR applications and servers to improve accuracy, formatting and performance. Use the OCR applications to convert the scanned images to text or searchable PDF, and SimpleIndex can extract index values from the text and automatically sort and organize the files.
- Published in OCR
How do you configure full text searching in Retrieval mode?
Please refer to the Wiki Documentation for the complete Database Settings reference.
On the Database tab there dropdown in the lower portion of the panel for Full Text OCR Field. Put the name of the field that will store the full-text data there. This must be configured both for Insert and Retrieval mode configurations. The database field needs to be sufficient length to store the entire text of your document.
Of course, the Insert Mode configuration must have “Enable Full Page OCR” checked to generate full text data from images. Text from MS Office documents, PDF files and existing OCR text files can be used without setting this option.
When designing your Retrieval Mode configuration, create a Text field to use for full text search queries. On the Database tab, set the corresponding “Database Field Name” to the full text database field.
When searching on your full text field, SimpleIndex finds the text you enter no matter where it appears in the document. It is able to match partial words. It does not perform boolean or natural language searches. The text entered must match the document text exactly.
- Published in Database & Retrieval, OCR
Can OCR text be saved to Office, Text, HTML or other formats?
Yes. On the OCR step of the Job Settings Wizard you can select the text output format need in the “Full-page OCR file type” drop down. By default it is set to PDF, but can be changed to Text (txt), Word (docx), Rich Text (rtf), Open Office (odt), Excel (xlsx), PowerPoint (pptx), ePub Zip (epub), FictionBook (fb2), HTML (htm), XML (xml) or Alto XML (alto.xml).

If the output file type is set to PDF, OCR text will be embedded as hidden text in the PDF file.
Related Links
- Published in Licensing & Installation, OCR
Can SimpleIndex create searchable PDF Image+Text files with hidden text?
Yes, it can. You can configure this setting in the Job Settings Wizard by going to the OCR step and checking “Enable full-page OCR”. There are many settings in the OCR step that you can used to customize the output and recognition of images.

SimpleIndex has two different OCR engines (Standard and Professional) that can be used to produced PDF Image + Text files or Searchable PDFs.
Related Links
- Published in Export, OCR, Office PDF Text Processing
The All-In-One Scanning & Sorting Tool

SimpleIndex® has the ability to perform a wide variety of scanning and document organization tasks quickly and easily.
This makes it a must-have tool for IT departments and consultants who often need to:
- Scan and store various documents on network shares or cloud storage
- Organize existing MS Office, PDF and other files on your network
- Attach files to records in a custom database
- Integrate scanning into custom business applications
- Add document capture to Robotic Process Automation bots
- Automate data entry from paper or electronic documents
- Reduce click charges for centralized scanning departments
With a cost and setup time that is negligible compared to other enterprise capture platforms, SimpleIndex makes sense even when your company already has one. For example:
- When SimpleIndex has unique features your other software doesn’t, like Office and PDF text parsing, PDF Bookmarking or Electronic Imprinting.
- When setting up a new workflow requires extensive setup time and management approvals to use the central system.
- When click charges make a project prohibitively expensive.
The wide variety of scanning and indexing tasks you can do with SimpleIndex make it an incredibly useful tool to have in your arsenal.

Find Out More
- Download or get an Online Demo
- SimpleIndex Feature Guide
- Wiki Manual Pages
- Compare Versions & Licensing
Learn More:
KB Articles for Document Management
- Oracle database is slow to respond
- What is Document Imaging?
- Using alternate database schemas
- Multiple Sort Fields on Search
- Access Database Connection String
- How do I delete an image and it's database entry?
- Is it possible to search for and retrieve documents with Windows desktop search?
- Will your SimpleQB allow me to scan in old invoices or bank statements directly into QuickBooks?
- How do I use the Media Wizard to create searchable DVDs or thumb drives?
- How do I export index data to a database?
Organize Office Documents with Text Parsing
This video shows the Sort My Documents sample job included with the SimpleIndex trial download. It shows how you can organize office documents automatically by parsing the file’s text for relevant metadata and keywords. You can then use those keywords to tag documents with metadata and create standardized folders and filenames.
First we sort Word documents, Excel spreadsheets and PowerPoint presentations automatically using the SimpleIndex template and dictionary matching algorithms that match patterns and keywords in the parsed text.
Then the files are organized into folders and filenames using the Sales Rep, Customer, Document Type and Date values extracted from the text.
Organize Office Documents for Cloud Storage
You can also upload organized files to SharePoint or Cloud Storage platforms without the chaos and disorganization you inevitably get when users create their own folders and filenames.
Organize Office Documents for Document Management
In the video, we use SimpleSearch to search and view the sorted files. But you can just as easily use any third party document management system or custom database to perform keyword or full-text searching.
You can use the SimpleView embedded viewer to view Office documents, PDF files and images in a common interface. In the video we use the full version of Word, Excel, and PowerPoint to edit Office documents right from the search screen.
Find Out More
- Download or get an Online Demo
- MS Office Text Processing Features in SimpleIndex
- MS Office Features and Settings Wiki Pages
- OCR Features and Settings Wiki Pages
- OCR Software Guide on SimpleOCR
Learn More:
Streamlined Interface
Maximum Data, Minimum Clicks



Learn More:
KB Articles for Streamlined Interface
- Indexing Solutions with Barcode Recognition
- The All-In-One Scanning & Sorting Tool
- Automatic Indexing Using Existing Data
- Take control of Sales Tax exemption forms
- Full-Page OCR Indexing Demo
- Video Demos
- Reduce Click Charges for Data Capture
- Network Scanners & Copiers
- Automated Processing & 1-Click Interface
- Features
PDF Text Processing Demo
This sample job demonstrates the PDF text processing capabilities of SimpleIndex by extracting the Document Number, Date, Document Type, Customer and Total from a number of documents without OCR, by processing the text layer of PDF files.
![]()
![]() Computer-generated PDF files, such as those created using PDF printer drivers, already contain digitized text. SimpleIndex reads the text and performs Template and Dictionary Matching to locate and extract the correct data values from the text.
Computer-generated PDF files, such as those created using PDF printer drivers, already contain digitized text. SimpleIndex reads the text and performs Template and Dictionary Matching to locate and extract the correct data values from the text.
Since the existing text is being used, OCR is not performed. This makes processing much faster and 100% accurate, especially compared to solutions using zone OCR.
While this demo runs interactively, text processing jobs can run in unattended mode since the data does not need to be verified.
Full-Page OCR can also be used to get text from scanned PDF files with no existing text. SimpleIndex will also detect when a PDF file has existing text and only perform OCR on the documents that need it to improve performance.
Find Out More
- Download or get an Online Demo
- PDF Text Processing Features in SimpleIndex
- PDF Features and Settings Wiki Pages
- Full-Page OCR Wiki Pages
- OCR Features and Settings Wiki Pages
- OCR Software Guide on SimpleOCR
Learn More:
FAQ Related to PDF Text Processing
- I have a duplex scanner. How to set up SimpleIndex to scan two sided documents automatically?
- Features
- Patent ID and Title Extraction
- Take control of Sales Tax exemption forms
- Instant Integration With Any Application
- Affordable Document Management
- Indexing Solutions with Barcode Recognition
- Document Classification
Video Demos
 These videos demonstrate several ways SimpleIndex® can automatically index different types of documents. If you are new to SimpleIndex, watching these videos is the easiest way to see what it can do. You can follow along using the sample files included in the SimpleIndex Trial.
These videos demonstrate several ways SimpleIndex® can automatically index different types of documents. If you are new to SimpleIndex, watching these videos is the easiest way to see what it can do. You can follow along using the sample files included in the SimpleIndex Trial.
- Zone OCR with template matching
- Document barcode recognition
- PDF OCR text parsing
- Sort and index MS Office documents
- Indexing with full-text OCR
- Running jobs from an icon
The sample files are copied to your Configuration Folder when you run the SimpleIndex Trial for the first time. If you can’t find the samples, copy them with the Global Settings Wizard in the File menu.
Compare Major Scanning Solutions
Integrated Solutions Built with SimpleIndex

Zone OCR with Template Matching

Document Barcode Recognition

PDF OCR Text Parsing

Sort and Index MS Office Documents

Full Page OCR Invoice Processing
Learn More:
- More products from Simple Software.
- How to create searchable PDF files using optical character recognition software?
- Convert scanned documents or PDF files to Excel, Google Sheets, CSV and other spreadsheet formats.
- Creating dataflow from text to Databases.
- Everything about Document Management
- Batch OCR for Full-Text Conversion & Searchable PDF.
- Enterprise OCR Servers let you perform OCR on thousands of documents at a time.
- OCR to process Invoices.
- What is OCR Data Capture?
- But what if I need to process a lot of specific medical forms (CMS 1500, UB-04, or J430 Dental Claims Forms)?
- OCR to process loan forms for Real Estate agents and Mortgage brokers.
KB Articles for Optical Character Recognition
- Language Pack for Standard/Tesseract OCR
- Languages Supported in SimpleSoftware OCR Engines
- What is Document Imaging?
- Change the Dictionary Separator Value
- Change the OCR Font or Type
- Regular Expression (RegEx) - Syntax or Type
- Autonumber Increment Value
- I'm using full page OCR. The information is all appearing in the txt file but it is losing format about half way through. Data to the right is ending up at the end of the txt doc. Can this be fixed?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- If I have a form which is filled manually by hand, can SimpleIndex read the data from it?
- 1
- 2
