 Use SimpleIndex to automate the process of assigning keyword index values to scanned documents and minimize data entry keystrokes and errors. SimpleIndex uses OCR with complex pattern matching to find index values anywhere on the page, or use bar codes to index scanned documents automatically.
Use SimpleIndex to automate the process of assigning keyword index values to scanned documents and minimize data entry keystrokes and errors. SimpleIndex uses OCR with complex pattern matching to find index values anywhere on the page, or use bar codes to index scanned documents automatically.
Once captured, structured data can be used to populate a database, document management system, SharePoint and other repositories.
SimpleIndex can simultaneously process MS Office, PDF, text, HTML and other files using the same pattern matching technology. If the file already has text it SimpleIndex uses it for increased speed and accuracy, falling back on OCR for images and scanned document indexing.

Patent ID and Title Extraction
To avoid manual data entry, pattern matching is used to automatically read the Patent ID Number and Title from any US patent application straight out of the box.
This job configuration is available for free for SimpleIndex users from the link below.
SimpleIndex Patents Demo Job Configuration
Learn More:









KB Articles for Patent ID and Title
- Language Pack for Standard/Tesseract OCR
- Languages Supported in SimpleSoftware OCR Engines
- What is Document Imaging?
- Change the Dictionary Separator Value
- Change the OCR Font or Type
- Regular Expression (RegEx) - Syntax or Type
- Autonumber Increment Value
- I'm using full page OCR. The information is all appearing in the txt file but it is losing format about half way through. Data to the right is ending up at the end of the txt doc. Can this be fixed?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- If I have a form which is filled manually by hand, can SimpleIndex read the data from it?
Take control of Sales Tax exemption forms
Automatically fill and file sales tax forms
Ben Franklin once noted, “…nothing is certain except death and taxes.” In the case of state sales taxes, they may be unavoidable, but managing your customers’ sales tax exemption forms and making sure you’ve sent current exemption certificates to your vendors doesn’t have to feel like a terminal condition.

SimpleIndex has the power to recognize the forms you receive from customers and file them automatically so you can find them in seconds.
SimpleIndex also fills out sales tax exemption PDFs from every state to create a complete set of your forms ready for emailing to your vendors.
Link both processes to your customer and vendor data sources to streamline the process. Even without those lists, the state, certificate number and expiration recognize automatically, leaving you with the simple task of clicking on the customer name to file the document away.

You’ll never have to dig through old emails or piles of paper to make sure you have that exemption on file again!
When it’s time to send your vendors the proper state certificate to get your sales tax exemption, simply open up the Fill Vendor Form job, select the vendor, and all your state exemptions are filled out automatically and assembled into one PDF file suitable for framing emailing.
Manage your customer sales tax exemption forms:
- Scan customer sales tax exemption certificates submitted on paper
- Process e-mailed PDF sales tax exemption forms
- Use OCR or read the filled-in forms from PDF files to file them automatically
- Search and view customer tax forms in seconds
- Receive automatic e-mail notifications when exemptions expire
Fill out and e-mail vendor sales tax exemption forms:
- Standardized, fillable PDF sales tax forms for every state
- Select a vendor and fill in all the relevant name and address information automatically
- One click fills in every state form with both your company’s information and your vendor’s
- Packages saved to bookmarked PDF files and e-mailed to vendors
- Receive automatic e-mail notifications when exemptions expire
Find out more!
The sales tax management solution is available for free to SimpleIndex users!
Download SimpleIndex – Download the Sales Tax Jobs
Some initial setup is required, and we can help you out with that too. Our Professional Services department can have you up and running in just a couple of hours.
Please Contact Us to find out more about automating your sales tax time thieves with SimpleIndex!
Learn More:
Indexing Solutions with Barcode Recognition
 Barcode recognition is the most efficient way to capture index data printed on documents. If you are unfamiliar with the use of barcodes in document scanning, you can learn more about barcodes in our Barcode Scanning Guide, but if you want to know more about barcode use with SimpleSoftware products, read on.
Barcode recognition is the most efficient way to capture index data printed on documents. If you are unfamiliar with the use of barcodes in document scanning, you can learn more about barcodes in our Barcode Scanning Guide, but if you want to know more about barcode use with SimpleSoftware products, read on.
Some documents already have key information in barcode format on them. In many cases adding a barcode to a document is as simple as changing or adding a font. Adding barcodes to new documents is preferable as all the index data is on the document at the time it is created and in a format that can be read with near 100% accuracy.
As an alternative to placing barcodes on the individual documents, it is possible to print out a barcode cover page and place it on the file before it is scanned. The SimpleCoversheet application was designed to make this easy by providing a simple interface for selecting index values and printing a standard coversheet that contains these values in barcode format.
Barcode recognition can also be useful when you have documents with a variable number of pages that will all receive the same index values. If it is not possible to generate an indexed coversheet for these at the time they are created, a generic barcode coversheet can be used to separate the scanned images into multi-page files, one for each document. A second process can then be used to index these images one file at a time instead of one page at a time, greatly increasing throughput.
Barcode Recognition Features
With SimpleIndex Barcode you can:
- Read barcodes printed on scanned paper documents
- Read barcodes embedded in PDF files
- Automatically rename files based on barcodes
- Export barcode data to CSV file or any database
- Separate multi-page documents with cover pages
- Recognize 2D formats like PDF417, DataMatrix, Aztec and QR Code
- Recognize 30 different 1D barcode formatsCode 39, Codabar, UPC, Code 128, EAN 13, 2 of 5, etc.
- Recognize postal barcodes like Planet, PostNet, Royal Post and Australian Post
- Lookup barcode values in a database for additional data
- Complete list of document scanning & indexing features
With SimpleCoversheet you can:
- Create barcode coversheets for use with SimpleIndex and other scanning applications
- Print barcodes on Avery label templates that can be applied to documents
- Affordably enable every employee to print barcodes
- Create coversheets that allow SimpleIndex to automatically index and file documents
- Enable scanning and indexing from MFPs, network scanners and digital copiers
- Perform “mail merge” with barcodes to print many coversheets at once
- Supports many 1D and 2D barcode formats
Learn More:
KB Articles for Barcode Recognition
- Turn On Replacement Characters for Barcodes
- Regular Expression (RegEx) - Syntax or Type
- Autonumber Increment Value
- What are some other terms for Bar Code Scanning Software?
- Can SimpleIndex read bar codes from existing PDF files?
- I cannot recognize PDF417 or QR Code bar codes. What does "Advanced "Only" mean?
- Can I split TIFF or PDF files based on barcodes as a separator and also name the file with the barcode value?
- Will SimpleIndex read multiple barcodes on a page and save the value to the appropriate index field?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- How can I delete the barcode or blank page cover/separator sheet that I don't need to save?
Zone OCR and Dynamic OCR

Other document scanning applications in this price range use Zone OCR to obtain index data from the page.
SimpleIndex improves upon this time-tested but limited model with its Dynamic OCR feature.
Let’s look at the difference between the two methods:
Zone OCR
Zone OCR is used to read document indexes or tags from text on the page. It is a great way to automate the data entry associated with scanning documents.
However, there are several limitations to zone OCR that must be overcome:
- Index information must be in the exact same place on every page
- Documents shift and skew during scanning, causing the zones to not line up
- If surrounding lines or text on the document are too close, they can encroach on the zone
Dynamic OCR
SimpleIndex overcomes these limitations by using Dynamic OCR technology to extract values from anywhere on the page. Our simplified version of Dynamic OCR works great for many types of documents at a fraction of the cost of other solutions.
- Index information can appear anywhere
- Unwanted characters are ignored
- Find unique patterns of letters and numbers using Template Matching
- Use Dictionary Matching to find a value from a list of possible values
- Use Cloud OCR or ChatGPT to perform AI analysis and intelligent data extraction
Dynamic OCR and AI Assisted OCR
AI assisted OCR is the popular solution to the problem of unstructured and semi-structured documents. But there are many scenarios where simple Template and Dictionary matching provide much better results. And all of these solutions are much more expensive than SimpleIndex!

Often there are only a few key values that need to be extracted, and a wide variety of possible layouts. AI-based document training requires manual processing of several samples of each possible format before it learns how to read them reliably, where a Template could read them all with a single setting. Dictionary matching can perform advanced classification without analyzing thousands of samples.
When data extraction requires natural language processing, field label extraction, handwriting, AI document analysis, or other advanced features, SimpleIndex offers Cloud OCR and ChatGPT integrations.
Dynamic OCR Examples
In the video we see how SimpleIndex approaches a typical Zone OCR example. With SimpleIndex you can use large zones that give a wide margin for error. Template and Dictionary matching are then used to extract the 7-digit Account Number, 6-digit Order Number and Company Name. SimpleIndex discards the surrounding text and keeps the correct value.
Another common example is finding a unique identifier, for example a social security number, that could appear anywhere on the page. Simply enter the template ###-##-#### and SimpleIndex will search the full OCR text until it finds a match. Since only one social security number is likely to appear on the page, a match on this pattern is almost certainly the required value.
With dictionary matching, you can give SimpleIndex a list of possible values and it will automatically search the zone or page for each possible value until it finds a match.
Many dynamic forms processing applications can be implemented using these simple algorithms. This makes SimpleIndex far more versatile than other zone OCR solutions that require the index value to be in the exact same location on every page. Yet SimpleIndex costs only a fraction of the price!
SimpleIndex‘s dynamic forms processing can greatly speed up data entry by eliminating a good percentage of indexing work. For many this can put the labor cost of scanning within their reach.
Dynamic OCR can also be applied to MS Office and PDF files, creating a fully automated process for intelligently indexing and reorganizing electronic documents.

Amazon AWS Textract Cloud OCR
With Textract you can capture data from almost any type of form, including handwritten ones! Textract identifies labeled text anywhere on the document and returns the label text along with the corresponding value. Map the labels to index fields in SimpleIndex and you are ready to capture that data no matter where it appears on the page.

Textract uses machine learning with a huge model based on the billions of pages processed using Textract to provide the most accurate OCR and form field extraction solution available.
By default, Textract is only available as an API and requires custom coding to integrate it into your document workflows. SimpleIndex turns it into a fully-featured batch document and data processing app that is ready to use out-of-the-box.
Since there are no templates to configure or train, setup can be done in hours instead of days or weeks months required by other enterprise data capture solutions.
Pay-as-you-go pricing makes SimpleIndex with Textract the most affordable way to batch process forms for projects with less than 50,000 pages per year to process, especially if you need to read handwriting or have forms with many layout variations.
Got a preference for ABBYY Cloud OCR, Microsoft Azure AI Vision, or Google Cloud Vision OCR? These can be quickly added for a small customization fee. Contact Us for a quote!
Wiki: How to configure AWS Textract OCR in SimpleIndex
Handprint and Handwriting Recognition

SimpleIndex 11 adds handprint recognition capabilities to the FineReader OCR engine to allow recognition of simple form fields and printed text. It works best with constrained form fields, with letter boxes for each character like you see on tax forms and credit applications. And no additional licensing or per-page costs are required!
For unconstrained handprint and cursive handwriting, use the Cloud OCR option to achieve the best recognition accuracy available. This option requires additional AWS processing fees for each page.
Support for Regular Expressions
SimpleIndex OCR has a simple built-in template format, as well as support for Regular Expressions. Regular Expressions (RegEx for short) let you define complex search patterns to extract matching values from the text. This greatly enhances the functionality of the dynamic OCR in SimpleIndex, making it capable of finding variable-length fields with no distinct pattern.
Regular Expressions are a commonly used in text parsing applications. The Perl programming language makes extensive use of RegEx, as do UNIX utilities like “grep”. Many programmers and IT personnel are already familiar with RegEx and can create complex expressions without specific training.
Click here for a reference guide to Regular Expressions
How to Configure SimpleIndex OCR
Our Wiki help has extensive information on how to configure OCR for various document and data capture scenarios.
- Zone OCR read data in a specific location
- Template matching to match unique patterns
- Dictionary matching to match a list of possible values
- OCR Options OCR job settings that apply to all fields
- File Formats that can be output by OCR
- Languages supported by OCR
- FineReader versus Tesseract OCR engines
- Searchable PDF with MRC compression
- OCR to Field for point and click OCR during verification
- Cloud OCR using Textract
Watch this Simple Software University training video to see how to configure and run an OCR job with SimpleIndex.
Learn More:
KB Articles for Optical Character Recognition (OCR)
- Language Pack for Standard/Tesseract OCR
- Languages Supported in SimpleSoftware OCR Engines
- What is Document Imaging?
- Change the Dictionary Separator Value
- Change the OCR Font or Type
- Regular Expression (RegEx) - Syntax or Type
- Autonumber Increment Value
- I'm using full page OCR. The information is all appearing in the txt file but it is losing format about half way through. Data to the right is ending up at the end of the txt doc. Can this be fixed?
- Is there a way to just use part of a bar code or OCR value? For example, extract "50" from the value "124450"
- If I have a form which is filled manually by hand, can SimpleIndex read the data from it?
Database Integration
Unprecedented Control of Database Interactions
 Open database integration is a powerful feature of SimpleIndex® that furthers interoperability with custom programs. Instead of using a proprietary database, SimpleIndex allows you to map index fields to cells in any database table. It can be configured to create new records, update existing ones, or retrieve them for viewing. Using these three basic database functions, SimpleIndex is able to interface with and operate on any database.
Open database integration is a powerful feature of SimpleIndex® that furthers interoperability with custom programs. Instead of using a proprietary database, SimpleIndex allows you to map index fields to cells in any database table. It can be configured to create new records, update existing ones, or retrieve them for viewing. Using these three basic database functions, SimpleIndex is able to interface with and operate on any database.
Automatic Indexing Using Existing Data
 SimpleIndex’s Autofill feature is an easy way to associate many index fields with one document without retyping data that already exists in another database. Autofill uses a database lookup to retrieve records that match key values entered by the user. Then blank index fields are automatically filled with the lookup data. After entering only one field, data autopopulates, resulting in a document database.
SimpleIndex’s Autofill feature is an easy way to associate many index fields with one document without retyping data that already exists in another database. Autofill uses a database lookup to retrieve records that match key values entered by the user. Then blank index fields are automatically filled with the lookup data. After entering only one field, data autopopulates, resulting in a document database.
The key field may be typed by the user or read from the document automatically using barcode recognition or OCR. The lookup is performed either when the user changes this field or when the index values are saved. If the lookup finds multiple matching records, the user will be notified and the first set of values will be used by default.
When used with pre-index batches, key information can be read automatically from barcodes or OCR and matched to database records with a single click.
Custom Code Extensions for Autofill and Export
 Customized Autofill and Export functions extend this functionality to use APIs and web services to populate or export index data when a direct database connection is not possible. This allows you to directly interface with any application to populate and export document data.
Customized Autofill and Export functions extend this functionality to use APIs and web services to populate or export index data when a direct database connection is not possible. This allows you to directly interface with any application to populate and export document data.
An example is our ChatGPT document analysis service, which uses the same extension interface to provide AI document analysis results that can be used for classification and natural language data extraction.
Match and Attach Mode
SimpleIndex features “Match and Attach” mode, which combines the power of the Autofill feature with the ability to update existing records in your database. This lets you “attach” images to existing database records by “matching” them with values from SimpleIndex.
XML and JSON Data Sources
SimpleIndex also has the ability to read data directly from XML and JSON files. Many document management and cloud storage platforms provide document metadata in XML and JSON files whenever you attempt to migrate data, along with corresponding files that may or may not have logical filenames. Use SimpleIndex to extract the data from these files, organize the documents, and migrate the metadata to a database or new document management platform.
Output to XML or Any Text Format

SimpleIndex offers direct export to pre-formatted XML files, as well as the SimpleExport module that can output any XML schema or text file format.
SimpleExport makes it possible to integrate with any third party database, application, or document management systems (DMS) that accept an XML or text file import.
SimpleExport converts the index values from a SimpleIndex job to any output format through XSL Transformations (xslt). You may use one of the built-in scripts to export to a pre-defined system or design your own. SimpleExport runs automatically after each batch is exported, or it can run as an unattended Windows service.
SimpleExport can also be used as a standalone application for automating XSLT transformations, converting CSV or TSV (delimited text files) to XML, converting images to base64, or integrating other scanning applications with third party software.
Find Out More
KB Articles for Database Integration
- Oracle database is slow to respond
- What is Document Imaging?
- Using alternate database schemas
- Multiple Sort Fields on Search
- Access Database Connection String
- How do I delete an image and it's database entry?
- Is it possible to search for and retrieve documents with Windows desktop search?
- Will your SimpleQB allow me to scan in old invoices or bank statements directly into QuickBooks?
- How do I use the Media Wizard to create searchable DVDs or thumb drives?
- How do I export index data to a database?
Exclude Index Field from Index Log
Please refer to the Wiki Documentation for the complete Index & Batch Logging reference.
Many times when outputting a Log file via CSV, XML, TXT, etc. there will be index fields that are required in the Job Configuration, but not desired to be output in the Index Log. In those cases those fields can be excluded from the Index Log with a “~” character at the end of the Index Field Name.
To do this go into the Job Options/Job Settings Wizard, go to the Index tab/step, find the Index field that you want to exclude from the Index Log and add this to the end of the field name: ~
EX. The original Index Name is “OCR Text” and that field should be excluded from the Index Log, so it doesn’t appear. This field should be changed to “OCR Text~”.
Change the Font Size of Index Fields
Please refer to the Wiki Documentation for the complete Index Fields reference.
Index fields have a default 8 point font size, but this can be changed if required for visibility. You can change this by editing a registry file in the Registry Editor and set any font size you would like.
To make this change follow these instructions
- Close out of SimpleIndex entirely
- Open the Windows Registry by going to the Windows Search and searching for “RegEdit”
- Go to this location in the Registry Folder Tree: Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
- In this window you will see a key called “IndexFontSize”.
- Open this file and change the value to the font size you would like and then click OK.
- Close and reopen SimpleIndex to see the change in effect.
Export Issues and Missing Images after Export
Please refer to the Wiki Documentation for the complete Export Settings reference.
If you are having issues with the files not exporting properly or you have missing images in the export folder that should have been saved, then a registry key needs to be added to correct this. This registry key changes the export process from the faster process that SimpleIndex uses by default, to a slower export process that will avoid these issues.
Instructions:
1. Search for
“regedit” on your computer.
2. Navigate to this
folder in the Registry Editor window:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
3. In the right
pane of the Registry Editor window Right Click and select New>String Value
4. Set the name of
the file to this: EnableAtalaExport
5. Double click on
the “EnableAtalaExport” registry key, set the Value to “0”
(Zero) and click OK.
FastImport to Disable Automatic Processing During Import
Please refer to the Wiki Documentation for the complete Fast Import Interface reference.
SimpleIndex has a variety of processing functions that automatically happen behind the scenes when importing documents to improve the quality and functionality of the images and processing capabilities of the software.
On some occasions these extra processing functions cause delays and conflicts or aren’t needed at all. If these processing functions are causing SimpleIndex to crash or slow down the import processing too much for a particular Job Configuration that can be turned off with a registry setting.
Follow these instructions to add this registry setting:
- Close out of SimpleIndex entirely
- Open the Windows Registry by going to the Windows Search and searching for “RegEdit”
- Go to this location in the Registry Folder Tree: Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
- In the right section of the Registry window Right Click in the white space and select New>String Value
- Name the new key “FastImport”
- Open the “FastImport” Registry Key, set the value to “1” and then click OK
Large Documents (>500 pages) are Slow to Process
When working with PDF image files containing a high number of pages (typically in excess of 500, but can vary by file and PC running the job) SimpleIndex may run into performance issues as it attempts to hold all of those pages in memory and perform the requested operations (full-text OCR in particular can tax a system in these circumstances).
SimpleIndex 11:
Use the Fast Import and Fast Export options to use our new, optimized import and export that can split or merge PDF files with thousands of pages in a matter of seconds. These options disable the optional features that require the slower import and export operations and allow for much faster processing.
Older Versions of SimpleIndex:
A workaround in this scenario is to convert the large PDF to a folder of smaller PDFs files that can be managed more easily. In order to minimize the impact on production and tax the user(s) with extra steps, you can use a third-party splitting tool that can be called from the Command Line. One such option that has worked well is PDFSplitter from CoolUtils
One way to automate this process is to use PDFSplitter’s command line ability in conjunction with SimpleIndex’s Pre-processing function. For simplicity let’s consider a 600 page PDF with a filename generated at the time of scanning using indexes provided on a coversheet or keyed by an operator. The goal now is to take that large file and perform a full-text conversion on it.
Our SimpleIndex job, Full Page OCR.sic let’s say, launches and before getting to work calls PDFSplitter from the Pre-processing step with a command such as
PDFSplitter.exe “C:\Images\Smith – John – Medical History.pdf” C:\Images\Pages\ -cp 100
PDFSplitter will run and break that document every 100 pages creating 6 PDFs in the folder C:\Images\Pages. It maintains the original filename, simply adding “001-100” and so on to the name. After PDFSplitter is complete the Full Page OCR job begins its process and, given that the original filename is still part of the split files’ naming schema, it can produce one full-text PDF in the final output folder.
Related Wiki Help Pages:
How to activate SimpleView?
Please refer to the Wiki Documentation for the complete SimpleView Application reference.
Activation Instructions
SimpleView Option A – New SimpleIndex Installation:
If you are installing SimpleView on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Demo Installation Link.Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.

During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:

Multiple Serial Codes (separate with a comma):

After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:

SimpleView Option B – SimpleView Already Installed:
If you have already installed the SimpleView software then all you need to do is Activate the demo.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.

Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.

You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleView Option C – SimpleView Installed on Computer Not Connected to the Internet:
If you would like to install SimpleView on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleView software without activation.
Click the SimpleView icon from the SimpleIndex software or from your Windows Start menu.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
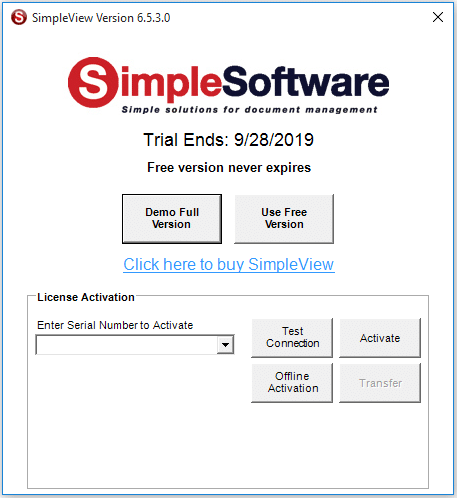
Click the “Offline Activation” button.

Click OK in the “SimpleView Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleView Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
How to activate any Add-on or Upgrade to SimpleIndex?
Please refer to the Wiki Documentation for the complete Licensing & Activation reference.
SimpleIndex Add-on Option A – New SimpleIndex Installation:
If you are installing SimpleIndex on the Windows computer for the first time first download SimpleIndex from the SimpleIndex Download Page.
Once the SimpleIndex software has been downloaded install the software from the downloaded installation file.
During the installation process you will be asked to enter your Serial Code or Serial Codes.
Single Serial Code:
Multiple Serial Codes (separate with a comma):
After you have entered your Serial Code(s) click Next to move through the installation process.
Once the installation is complete you will receive the following Window:
When you click Finish you will receive the Global Settings Wizard window to configure the general settings for SimpleIndex on the installed computer.

Move through the prompts to configure the Global Settings Wizard. Once complete you will receive a confirmation that the License was properly activated before the software opens.
SimpleIndex Add-on Option B – SimpleIndex Already Installed:
If you have already installed the SimpleIndex software then all you need to do is Activate the demo.
Click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and Select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.

Click the Activate button to activate the license.
You will receive a confirmation that the license was properly activated and your license type will be displayed next to the “License Type:” section of the Activation Window.
SimpleIndex Add-on Option C – SimpleIndex Installed on Computer Not Connected to the Internet:
If you have installed SimpleIndex on a computer that doesn’t have an internet connection an Offline Activation will need to be done.
First fully install the SimpleIndex software without activation.
Once it has been fully installed click the SimpleIndex icon on your desktop or from your Windows Start menu.

Once SimpleIndex is open go to the Help menu and select Activate/Transfer License.
Enter your Serial Number into the “Enter Serial Number to Activate” field in the Activation Window.
Click the “Offline Activation” button.
Click OK in the “SimpleIndex Offline Activation” window, which asks you to call or email for an Offline Activation.

Select the license version that you ordered in the “SimpleIndex Version” drop down.
Then either call (865) 637-8986 option 2 or email support@simpleindex.com with the Authorization Request Code. We will the provide you with the Activation Key.
Enter the Activation Key and then click the Offline Activation button.
Maintenance is optional, but covers tech support and upgrades for the software. Please consider purchasing maintenance if you haven’t already. Please refer to Simple Software Maintenance Agreement for more information.
TaxStacker: Sort & Classify Federal Tax Documents
This is a great way for accountants and tax preparers to organize complex tax returns in a way that makes it easy to find specific documents. It can also be used to ensure all required schedules and supporting documents are present in the finished return.
Use our out-of-the-box TaxStacker configuration to automatically identify all the forms and schedules that make up a U.S. federal income tax return. These can then be sorted into separate PDF files or combined into a single file that has bookmarks to indicate each section.
Learn More:
Enable Post-Process when Input Folder is Empty
Please refer to the Wiki Documentation for the complete Advanced Settings reference.
When you have multiple Job Configurations running in tandem with the Post-Process command line running one after there other there can be occasions where a Job Configuration earlier in the chain doesn’t have any images in the Input folder. When this happens a prompt occurs that must be clicked to proceed to the the next Job Configuration. When running unattended this can cause issues when the process stops for this prompt. This can be turned off in the Job Configuration’s XML settings.
Instructions for suppressing prompt to continue when Input folder is empty:
- Right click on the Job Configuration file that you would like to suppress the prompt on and select Open With>Notepad
- Search the XML settings text open in Notepad for this term:
<POSTPROCEMPTY> - Set the value between from “True” to “False”. It should look like this:
<POSTPROCEMPTY>False</POSTPROCEMPTY> - Save and close the file.
Disable StopFile
Please refer to the Wiki Documentation for the complete File Input Settings reference.
If you have many different users running SimpleIndex on different computers saving to the same Output folder, the STOPFILE from one can cause another user to not be able to export to the folder while the original user is outputting to the folder. In this case the STOPFILE can be disabled, so this no longer happens.
This will not work if you have anyone that needs to add files to an existing file in the output folder, so make sure that won’t happen.
Instructions:
- Close SimpleIndex entirely
- Open the Windows Registry by going to the Windows Search and searching for “RegEdit”
- Go to this location in the Registry Folder Tree: Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc
- In the right section of the Registry window Right Click in the white space and select New>String Value
- Name the new key “StopFile”

Index With Non-Latin Character Sets
Please refer to the Wiki Documentation for the complete Languages reference.
By default SimpleIndex uses the ANSI character set to display and edit captured OCR data, index field values and full-text OCR. This works for all languages based on the Latin alphabet (English, French, Spanish, German, etc.)
To index documents in other languages like Chinese, Japanese, Russian, Arabic and other non-Latin alphabets, set the default character set using this registry key. If the key is not set correctly then Unicode text will show up as ??????????.
Use Notepad to edit the “Charset” value from the sample setting below and save it to a .reg file. Then double-click the .reg file to install (Administrator privileges required).
You can download the .reg file here but you still need to edit in Notepad to set the Charset value before installing.
If you are on a 32-bit operating system be sure to remove the extra “\WOW6432Node” from the registry path.
[HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\SimpleIndex\Misc]“Charset”=”1”
| Charset Name | Charset Value |
| ANSI_CHARSET (Latin) | 0 |
| DEFAULT_CHARSET | 1 |
| SYMBOL_CHARSET | 2 |
| SHIFTJIS_CHARSET (Japanese) | 128 |
| HANGUL_CHARSET (Korean) | 129 |
| GB2312_CHARSET (Simplified Chinese) | 134 |
| CHINESEBIG5_CHARSET (Chinese) | 136 |
| GREEK_CHARSET (Greek) | 161 |
| TURKISH_CHARSET (Turkish) | 162 |
| HEBREW_CHARSET (Hebrew) | 177 |
| ARABIC_CHARSET (Arabic) | 178 |
| BALTIC_CHARSET (Baltic) | 186 |
| RUSSIAN_CHARSET (Russian) | 204 |
| THAI_CHARSET (Thai) | 222 |
| EE_CHARSET | 238 |
| OEM_CHARSET | 255 |

The full list of values is at https://msdn.microsoft.com/en-us/library/cc194829.aspx.
Skip to Blank Index on Save Index
Please refer to the Wiki Documentation for the complete Index & Batch Logging reference.
If you would like to have SimpleIndex automatically go to the next page with a blank field and highlight that field when the Save Index button or Enter a change to the XML text of the Job Configuration is needed. This can be useful to quickly move to the next document that has a blank Index field.
Instructions to set Skip to Blank index on Save Index:
- Right click on the Job Configuration file that you would like to suppress the prompt on and select Open With>Notepad
- Search the XML settings text open in Notepad for this term:
<SKIP_TO_NEXT_BLANK> - Set the value between from “False” to “True”
<SKIP_TO_NEXT_BLANK>True</SKIP_TO_NEXT_BLANK> - Save and close the file.
Stop Autorun When Double Clicking Configuration
Please refer to the Wiki Documentation for the complete Settings Wizard reference.
SimpleIndex jobs can be launched from an icon, just like opening a Word document saved on your desktop. However when you do this the default behavior is to automatically run the job file once it opens in SimpleIndex. If you just want to open the job without running it, follow these instructions:
1. Create a shortcut to the configuration by right clicking on the configuration file and selecting “Create shortcut”
2. Right click on the Shortcut that was just created and saved and select “Properties”
3. In the “Target” field put the following:
“C:\Program Files (x86)\SimpleIndex\SimpleIndex.exe” /c:”<Full Path to Configuration file>” /m
Example:
“C:\Program Files (x86)\SimpleIndex\SimpleIndex.exe” /c:”C:\Images\test.sic” /m

Forward Blank Index Fields
Please refer to the Wiki Documentation for the complete Index Fields reference.
To turn on the carry Forward when you blank out an index field do the following:
1. Right click on the configuration file and open with Notepad or another text editor.
2. Search for this XML value: FORWARD_BLANK
3. Set the value to true
Viewer Reset for SimpleIndex
Please refer to the Wiki Documentation for the complete SimpleView Application reference.
If you have any issues with the SimpleView viewer within SimpleIndex not displaying properly or the grid size being off you can reset it by doing the following.
1. Go to the Registry by searching for regedit
2. Locate this folder path:
hkey_current_user\software\vb and vba applications\simpleindex
OR
hkey_current_user\software\vb and vba program settings\simpleindex
3. Delete the SimpleIndex folder from that path, which deletes all the saved user settings and reverts back to default.

